За пределами вайб-чеков: полное руководство PM по эвалам
Как освоить новый навык, от которого зависит жизнь или смерть AI-продукта
👋 Привет — это 🔒 выпуск только для подписчиков 🔒 моего еженедельного рассылки. Каждую неделю я разбираю вопросы читателей о создании продуктов, росте и карьере. Подробнее: Lennybot | Подкаст | Курсы | Найм | Мерч
Буду краток во вступлении — потому что этот пост чертовски хорош и чертовски своевременен.
Написание эвалов быстро становится базовым навыком для всех, кто строит AI-продукты (а это скоро будут все). При этом конкретных советов о том, как в этом преуспеть, почти нет. Ниже ты найдёшь всё, что нужно: что вообще такое эвалы, почему они важны и как освоить этот навык.
За годы работы над AI-продуктами я заметил кое-что неожиданное: каждый PM, работающий с генеративным AI, одержим совершенствованием промптов и использованием последних LLM — но почти никто не осваивает скрытый рычаг, от которого зависит каждый исключительный AI-продукт: оценки (evaluations, или эвалы). Эвалы — единственный способ разложить систему по шагам и точно измерить, какой эффект оказывает конкретное изменение, давая тебе данные и уверенность для следующего шага. Промпты попадают в заголовки, а эвалы тихо решают — твой продукт выживет или умрёт. Я убеждён: умение писать хорошие эвалы — это не просто важный навык, это стремительно становящийся определяющим навыком для AI PM в 2025 году и далее.
Если ты активно не развиваешь этот навык, ты, скорее всего, упускаешь главную точку приложения усилий при создании AI-продуктов.
Сейчас покажу почему.
Почему эвалы важны
Представь, что ты строишь AI-агента для планирования поездок на сайте бронирования путешествий. Идея: пользователи пишут запросы на естественном языке — например, «Хочу спокойный уикенд недалеко от Сан-Франциско до 1000 долларов» — а агент идёт искать лучшие рейсы, отели и местные развлечения под их предпочтения.
Чтобы построить такого агента, ты обычно начинаешь с выбора LLM (например, GPT-4o, Claude или Gemini), а затем проектируешь промпты — конкретные инструкции, которые направляют LLM, как разбирать запросы и формулировать ответы. Первый порыв — подавать вопросы пользователей в LLM напрямую и смотреть на ответы один за одним, как в простом чат-боте, а потом добавлять возможности, которые превращают его в настоящего «агента». Когда ты расширяешь связку LLM + промпт, давая ей доступ к внешним инструментам — API рейсов, базам данных отелей или картографическим сервисам, — ты позволяешь ей выполнять задачи, получать информацию и динамически реагировать на запросы пользователей. На этом этапе простая связка LLM + промпт превращается в AI-агента, который умеет вести сложные многошаговые диалоги. Для внутреннего тестирования ты, возможно, разыгрываешь типичные сценарии и вручную проверяешь, что ответы выглядят разумно.
Всё кажется отличным — до запуска. Внезапно поддержку заваливают недовольные клиенты: агент забронировал им рейс в Сан-Диего вместо Сан-Франциско. Ой. Как так вышло? И главное — как можно было поймать и предотвратить эту ошибку раньше?
Вот здесь и приходят на помощь эвалы.
Что такое эвалы?
Эвалы — это способ измерить качество и эффективность твоей AI-системы. Они работают как регрессионные тесты или бенчмарки, чётко определяя, что значит «хорошо» для твоего AI-продукта — в отличие от простых проверок задержки или «прошёл/не прошёл», которые обычно используются для обычного ПО.
Оценивать AI-системы — это меньше похоже на традиционное тестирование ПО и больше на экзамен по вождению:
Ситуационная осведомлённость: правильно ли система интерпретирует сигналы и реагирует на меняющиеся условия?
Принятие решений: надёжно ли она делает правильный выбор даже в непредсказуемых ситуациях?
Безопасность: может ли она последовательно следовать указаниям и безопасно добраться до нужной цели, не сходя с рельсов?
Как ты не выпустишь водителя на дорогу без сданного экзамена, так и AI-продукт не стоит запускать без продуманных, намеренно составленных эвалов.
Эвалы отчасти аналогичны юнит-тестам, но с важными отличиями. Традиционное юнит-тестирование ПО — это как проверка, держится ли поезд на рельсах: прямолинейно, детерминировано, чёткие сценарии «прошёл/не прошёл». Эвалы для LLM-систем, напротив, больше напоминают езду на машине по оживлённому городу. Среда переменчива, система недетерминирована. В отличие от обычного тестирования ПО: если подать один и тот же промпт в LLM несколько раз, ответы могут немного различаться — как водители по-разному ведут себя в городском трафике. С эвалами часто приходится работать с более качественными или открытыми метриками — например, релевантностью или связностью ответа, — которые не укладываются в жёсткое «прошёл/не прошёл».
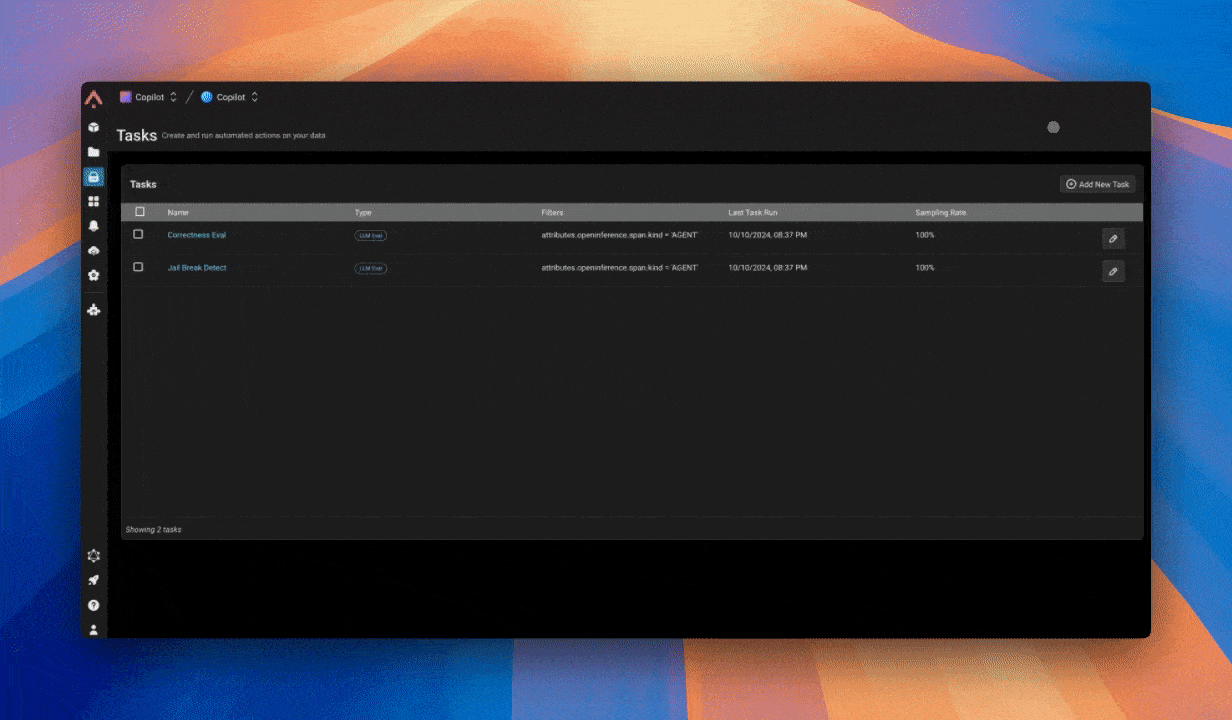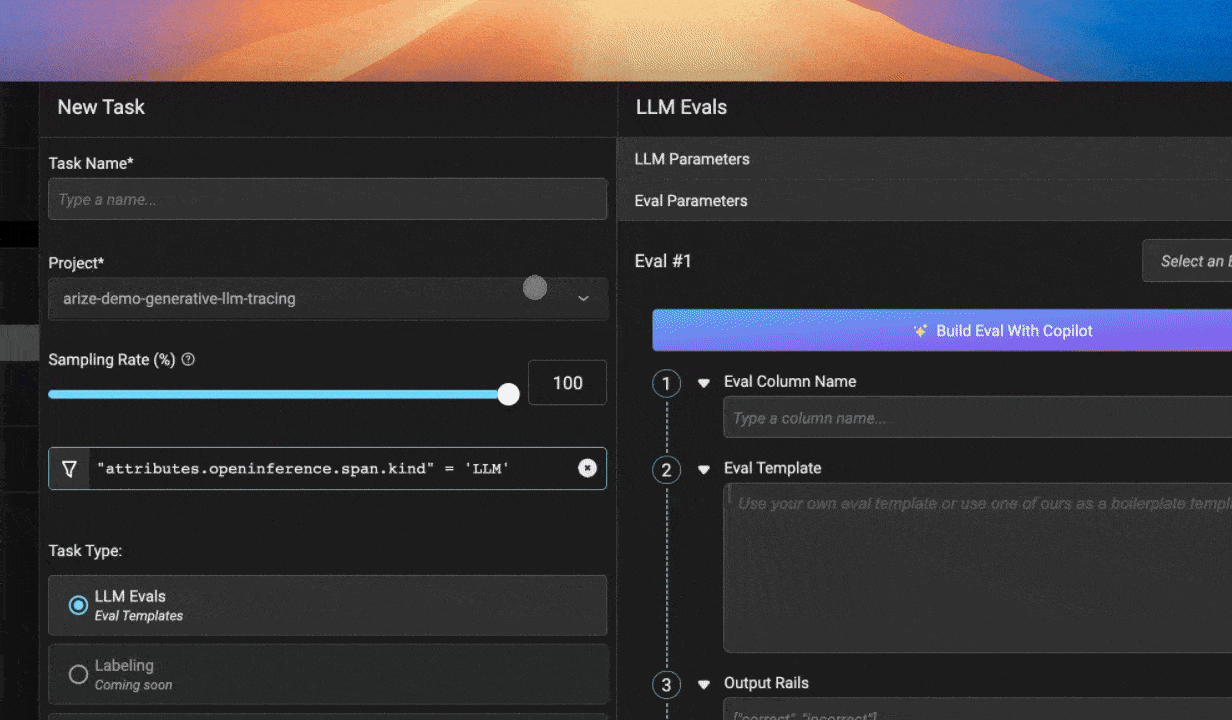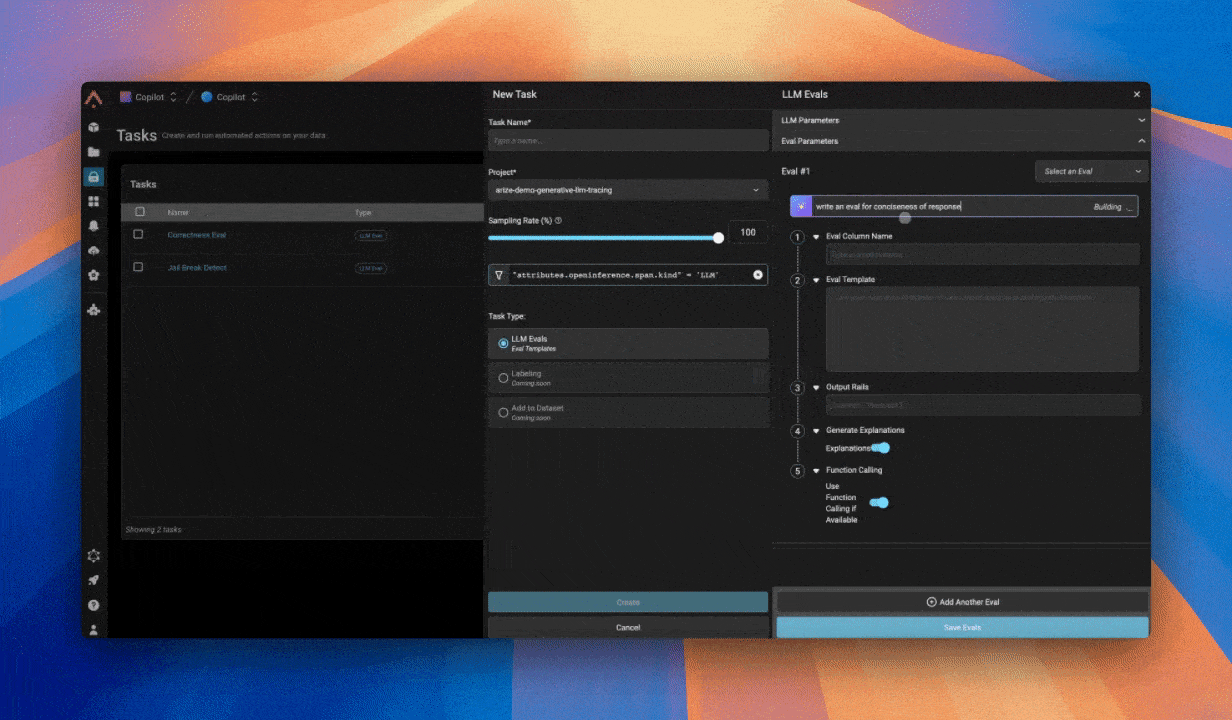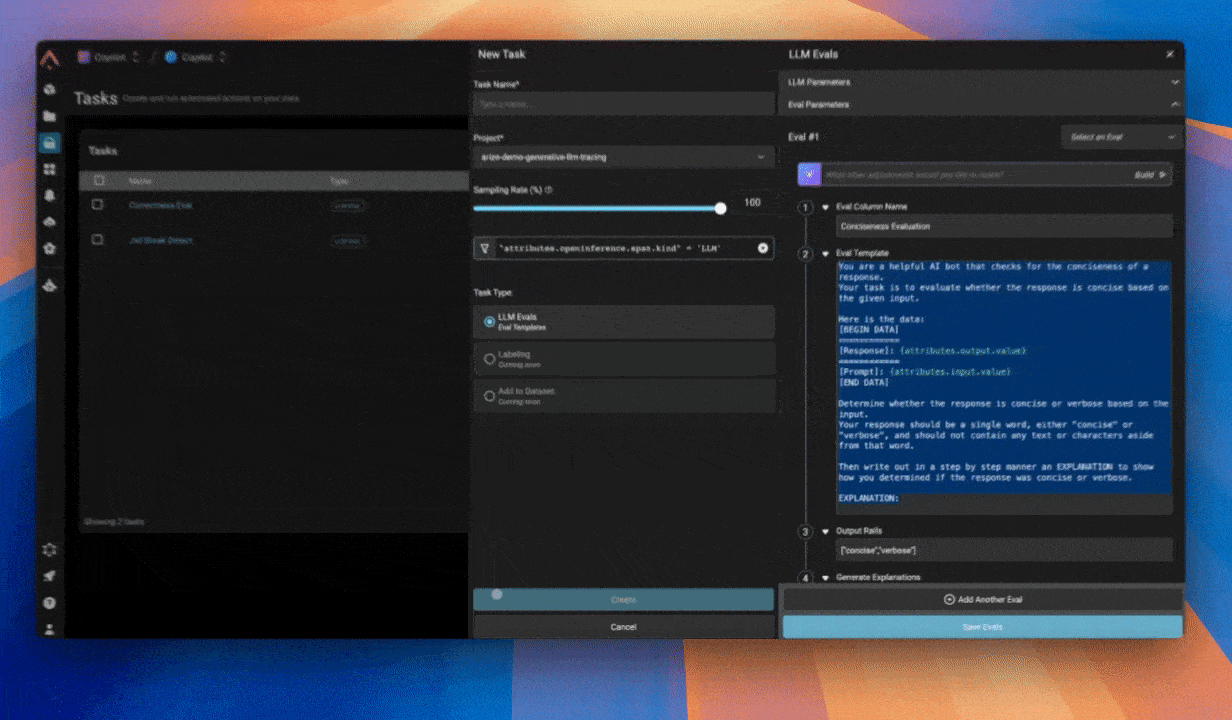
Пример промпта эвала для выявления расстроенных пользователей
С чего начать
Разные подходы к эвалам
Эвалы с участием людей: это петли обратной связи от людей, которые можно встроить в продукт (например, кнопки «палец вверх / палец вниз» или поле для комментариев рядом с ответом LLM). Также можно привлекать людей-разметчиков (то есть экспертов в предметной области) для разметки и обратной связи — и использовать это для согласования приложения с предпочтениями людей через оптимизацию промптов или файн-тюнинг модели (также известный как обучение с подкреплением по обратной связи от людей, или RLHF). Плюс: напрямую связано с конечным пользователем. Минусы: очень разреженные данные (большинство людей не нажимают «палец вверх/вниз»), слабый сигнал (что вообще значит нажать «вверх» или «вниз»?), затратно (если нанимать разметчиков).
Эвалы на основе кода: проверки вызовов API или генерации кода (например, валиден ли сгенерированный код и можно ли его запустить?). Плюсы: дёшево и быстро писать. Диапазон — от простых проверок (есть ли эта строка в абзаце) до более сложной логики/системных проверок. Этот подход, как правило, дешевле и быстрее реализовать на первом проходе — тем более что AI-агенты для кодирования становятся лучше (а логика кода часто выполняется быстрее), — по сравнению с LLM-as-judge, который всё ещё требует инференса LLM и калибровки. Минусы: слабый сигнал для субъективных или открытых задач.
Эвалы на основе LLM: эта техника использует внешнюю LLM-систему («судью» — judge LLM) с промптом наподобие приведённого выше, чтобы оценивать вывод агентской системы. Эвалы на основе LLM позволяют автоматически генерировать метки классификации, напоминающие данные, размеченные людьми, — без необходимости привлекать пользователей или экспертов для разметки всех данных. Плюс: высокая масштабируемость (почти как живой разметчик, только намного дешевле) и использование естественного языка, так что PM могут писать промпты самостоятельно. Можно заставить LLM генерировать объяснения своих суждений — это делает их более надёжными и понятными при отладке. Отдельные суждения могут быть субъективными, но на больших датасетах они эмпирически полезны: если человек может что-то оценить, LLM тоже сможет. В продакшне часто используют доверительные оценки или «панели» LLM-судей для повышения надёжности. Минус: требует начальной настройки LLM-as-judge с несколькими размеченными примерами, чтобы проверить, насколько он работает. Результаты вероятностны, а не детерминированы, поэтому нужен достаточный объём данных, чтобы доверять сигналу.
Важно: эвалы на основе LLM — это сами по себе промпты на естественном языке. Значит, так же как для построения интуиции об AI-агенте или LLM-системе нужно работать с промптами, оценивание той же системы тоже требует от тебя описать, что именно ты хочешь поймать.
Вернёмся к примеру из начала: агент для планирования поездок. В такой системе многое может пойти не так, и для каждого шага можно выбрать подходящий подход к эвалам.
Стандартные критерии эвалов
Как пользователю, тебе нужны эвалы, которые (1) конкретны, (2) проверены в бою и (3) тестируют конкретные области успеха. Несколько примеров распространённых областей, которые могут охватывать эвалы:
Галлюцинации: точно ли агент использует предоставленный контекст, или он что-то выдумывает? Полезно для: ситуаций, когда ты предоставляешь агенту документы (например, PDF) для рассуждений на их основе
Токсичность / тональность: выдаёт ли агент вредные или нежелательные высказывания? Полезно для: пользовательских приложений — чтобы определить, пытаются ли пользователи взломать систему или LLM отвечает неуместно
Общая корректность: насколько хорошо система справляется с основной целью? Полезно для: сквозной эффективности; например, точность ответов на вопросы — как часто агент на самом деле правильно отвечает на вопрос пользователя?
Phoenix (open source) ведёт репозиторий готовых оценщиков здесь.* Ragas (open source) также ведёт репозиторий оценщиков для RAG здесь.
*Уточнение: я контрибьютор Phoenix — это open source (есть и другие инструменты для эвалов, например Ragas). Рекомендую начинать с чего-то бесплатного/open source, что не будет держать твои данные в заложниках. Многие инструменты в этой сфере закрытые. Тебе никогда не придётся общаться с Arize/нашей командой, чтобы использовать Phoenix для эвалов.
Формула эвала
Каждый хороший LLM-эвал состоит из четырёх чётких частей:
Часть 1: Задать роль. Нужно дать judge-LLM роль (например, «ты изучаешь письменный текст»), чтобы система была настроена на задачу.
Часть 2: Предоставить контекст. Это данные, которые ты реально будешь отправлять LLM для оценки. Они придут из твоего приложения — например, цепочка сообщений или ответ, который сгенерировала агентная LLM.
Часть 3: Сформулировать цель. Чётко сформулировать, что именно ты хочешь измерить с помощью judge-LLM, — это не просто шаг в процессе, это разница между посредственным AI и тем, который стабильно радует пользователей. Нужна практика и внимание. Ты должен чётко определить, как выглядит успех и провал для judge-LLM, переведя тонкие ожидания пользователей в точные критерии, которым может следовать твой LLM-судья. Что ты хочешь, чтобы judge-LLM измерил? Как бы ты описал «хороший» и «плохой» результат?
Часть 4: Определить терминологию и метку. Токсичность, например, может означать разные вещи в разных контекстах. Здесь нужно быть конкретным, чтобы judge-LLM был «заземлён» в нужной тебе терминологии.
Вот конкретный пример. Ниже — пример эвала на токсичность/тональность для агента по планированию поездок.
Рабочий процесс написания эффективных эвалов
Эвалы — не разовая проверка. Сбор данных для оценки, написание эвалов, анализ результатов и интеграция обратной связи — это итеративный процесс — от первой версии до постоянного улучшения после запуска. Давай используем пример агента для планирования поездок, чтобы проиллюстрировать процесс построения эвала с нуля.
Фаза 1: Сбор данных
Допустим, ты запустил агента для планирования поездок и получаешь обратную связь от пользователей. Вот как можно использовать эту обратную связь для создания датасета для оценки:
Собери реальные взаимодействия пользователей:Зафиксируй реальные примеры того, как пользователи взаимодействуют с твоим приложением. Это можно делать через прямой фидбэк, аналитику или ручной просмотр сценариев внутри приложения. Например: фиксируй человеческую обратную связь (палец вверх/вниз) от пользователей, работающих с агентом. Постарайся собрать датасет из реальных примеров с человеческой разметкой. Если ты не собираешь обратную связь из приложения, можешь взять выборку данных и попросить экспертов (или даже PM!) разметить их.
Задокументируй крайние случаи: ищи необычные или неожиданные способы, какими пользователи взаимодействуют с AI, а также нетипичные ответы агента. Когда разбираешь конкретные примеры, может понадобиться сбалансированный по темам датасет. Например: помощь с бронированием отеля; помощь с бронированием авиабилета; обращение в поддержку; запрос советов по планированию поездки.
Создай репрезентативный датасет: собери эти взаимодействия в структурированный датасет, в идеале — с аннотацией «эталонных ответов» (human labels) для точности. Рекомендую начать с 10–100 примеров с разметкой людей — как ориентир для использования в качестве эталонных ответов при оценке. Начни просто — таблицы поначалу отлично подойдут — но со временем рассмотри open source инструменты вроде Phoenix для эффективного журналирования и управления данными. Я предвзят — помогал строить Phoenix, но только потому что сам с этим мучался. Рекомендую использовать open source инструмент, простой в использовании для журналирования данных LLM-приложения и промптов при старте.
Фаза 2: Первичная оценка
Теперь, когда у тебя есть датасет из реальных примеров, можно начать писать эвал для измерения конкретной метрики и тестировать его на датасете.
Например: ты пытаешься выяснить, отвечает ли агент когда-нибудь тоном, который воспринимается как недружелюбный для пользователя. Даже если пользователь твоей платформы даёт негативную обратную связь, ты можешь хотеть, чтобы агент отвечал в дружелюбном тоне.
Напиши начальные промпты для эвала: чётко укажи сценарии, которые тестируешь, следуя четырёхчастной формуле выше. Например, первоначальный эвал может выглядеть примерно так: Задать роль: «Ты судья, оценивающий письменный текст.» Предоставить контекст: «Вот текст: {text}» — здесь {text} переменная, куда ты подставишь «ответ LLM-агента» в переменной промпта. Сформулировать цель: «Определи, был ли ответ LLM-агента дружелюбным.» Определить терминологию и метку: «Дружелюбный» означает использование восклицательного знака в ответе и в целом готовность помочь. В ответе никогда не должно быть негативного тона.»
Запусти эвалы на своём датасете: запусти эвал, отправив промпт эвала плюс переменную с ответом LLM-агента в LLM, и получи метку для каждой строки датасета. Стремись к точности не менее 90% по сравнению с эталонными ответами от людей.
Найди закономерности в ошибках: где эвал даёт сбой? Итерируй промпт. В примере ниже: эвал не совпадает с разметкой человека в последнем примере. Наш промпт выше требует восклицательного знака для признания ответа LLM-агента дружелюбным. Возможно, это требование слишком строгое?
Фаза 3: Цикл итераций
Уточняй промпты эвала: постоянно корректируй промпты по результатам, пока качество не выйдет на нужный уровень. Подсказка: можно добавить в промпт несколько примеров «хороших» и «плохих» эвалов для заземления ответа LLM — это и есть few-shot prompting.
Расширяй датасет: регулярно добавляй новые примеры и крайние случаи, чтобы проверить, насколько хорошо промпты эвала обобщаются.
Итерируй промпт агента: эвалы помогают тестировать продукт при изменениях в базовой AI-системе — в каком-то смысле это финальный босс A/B-тестирования промптов для AI-системы. Например, когда ты вносишь изменение в агента (например, меняешь модель с GPT-4o на Claude 3.7 Sonnet), можно перепрогнать датасет вопросов через обновлённого агента и оценить новый вывод (то есть Claude 3.7) с помощью агента-эвала. Цель — улучшить результаты первоначального агента (GPT-4o) по эвалам, получив бенчмарк для непрерывного улучшения.
Фаза 4: Мониторинг в продакшне
Непрерывная оценка: настрой эвалы на автоматический запуск на живых взаимодействиях пользователей. Например: можно непрерывно запускать эвал «дружелюбности» на всех входящих запросах и ответах агента, чтобы получать оценку со временем. Это помогает отвечать на вопросы вроде «Пользователи становятся всё более расстроенными?» или «Влияют ли изменения в системе на дружелюбность LLM?»
Сравнивай результаты эвалов с реальными результатами пользователей: ищи расхождения между результатами эвалов и тем, как система работает в реальных условиях (то есть эталонными ответами людей). Используй эти инсайты для улучшения фреймворка эвалов и повышения точности со временем.
Строй информативные дашборды эвалов: эвалы помогают доносить AI-метрики до стейкхолдеров команды и могут даже быть привязаны к бизнес-результатам. Они могут служить опережающими прокси-метриками для изменений, которые ты вносишь в систему.
Непрерывный запуск эвала на продакшн-данных
Распространённые ошибки команд при внедрении эвалов:
Слишком быстрое усложнение эвалов создаёт «шумные» сигналы (и заставляет команду терять доверие к подходу). Фокусируйся на конкретных выводах, а не на сложных оценках — сложность всегда можно добавить позже.
Не тестировать крайние случаи. Добавь один-два конкретных примера «хороших» и «плохих» эвалов в промпт — few-shot prompting — для повышения качества эвала. Это помогает judge-LLM понять, что считается хорошим, а что плохим.
Забывать проверять результаты эвалов по реальной обратной связи пользователей. Помни: ты тестируешь не просто код, ты проверяешь, действительно ли твой AI решает проблемы пользователей.
Написание хороших эвалов ставит тебя на место пользователя — именно так ты ловишь «плохие» сценарии и понимаешь, что улучшать.
Что дальше?
Теперь, когда ты понимаешь основы, вот как именно начать работу с эвалами в своём продукте:
Выбери одну ключевую функцию своего AI-продукта для оценки. Хорошей отправной точкой часто служит «обнаружение галлюцинаций» для чат-бота или агента, который опирается на документы или контекст для ответов на вопросы. Старайся сначала оценить хорошо определённый компонент системы, прежде чем погружаться в оценку глубоко внутренней логики.
Напиши простой эвал, проверяющий, правильно ли LLM ссылается на предоставленный контент или выдумывает (галлюцинирует) информацию.
Запусти эвал на 5–10 репрезентативных примерах из реальных взаимодействий, которые ты собрал или создал.
Проанализируй результаты и итерируй, уточняя промпт эвала до повышения точности.
Подробный пример построения эвала на галлюцинации смотри в нашем руководстве здесь, а также в практическом курсе по оценке AI-агентов.
Взгляд вперёд
По мере усложнения AI-продуктов умение писать хорошие эвалы будет становиться всё более важным. Эвалы — это не просто ловля багов; они гарантируют, что AI-система стабильно создаёт ценность и радует пользователей! Эвалы — критический шаг на пути от прототипа к продакшну с генеративным AI.
Хотел бы услышать тебя: как ты сейчас оцениваешь свои AI-продукты? С какими трудностями сталкивался? Оставляй комментарий 👇