
Фреймворк, как классифицировать и приоритизировать агентские инициативы
👋 Привет, я Lenny. Каждую неделю я отвечаю на вопросы читателей про продакт, рост и ускорение карьеры. Ещё больше: Lenny's Podcast | Lennybot | How I AI | мои любимые AI/PM курсы, курс по публичным выступлениям, copilot для подготовки к собеседованиям
P.S. Забирай бесплатный годовой доступ к Lovable, Manus, Replit, Gamma, n8n, Canva, ElevenLabs, Amp, Factory, Devin, Bolt, Wispr Flow, Linear, PostHog, Framer, Railway, Granola, Warp, Perplexity, Magic Patterns, Mobbin, ChatPRD и Stripe Atlas — стань Insider-подписчиком. Да, это всерьёз.
Агенты сейчас на пике. Чуть ли не каждый день кто-то запускает нового или новый инструмент для управления ими. Уверен, у твоей команды прямо сейчас в бэклоге с полдюжины агентских идей. Это не значит, что сегодня нужно кровь из носу строить агента. Но значит, что ты обязан понимать, как агенты вписываются в твою стратегию и какие инвестиции тут уместны.
Hamza Farooq и Jaya Rajwani ведут два из самых высокорейтинговых и уважаемых курсов по сборке AI-агентов (Agent Engineering Bootcamp и Agentic AI for PMs) и потратили больше 50 часов на этот гайд. К концу поста ты поймёшь три типа агентов, как приоритизировать инициативы и как избегать типичных ловушек — с конкретными инструментами, платформами и кучей живых примеров.
Поехали.
P.S. Можешь послушать этот пост как подкаст: Spotify / Apple / YouTube.
За последний год мы провели один и тот же разговор минимум 30 раз. AI-лид открывает свой roadmap — обычно 5-10 «агентских» инициатив — и говорит: «Помоги нам понять, что строить первым».
Список обычно включает PM-ассистента, RAG-copilot, систему клиентской поддержки, code review агента и шопинг-ассистента с голосом.
Если ты это читаешь, скорее всего, у тебя похожий список. Команда горит, инвесторы спрашивают, конкуренты анонсят. Нужно что-то выбрать и отгрузить.
Вот тут большинство команд и застревает. Проблема не в нехватке идей — проблема в том, что они пытаются приоритизировать принципиально разные системы как одно и то же. Привычный подход — открыть матрицу impact-vs-effort и сравнить идеи бок о бок.
Но с AI-агентами это быстро разваливается. Один «агент» строится шесть недель. Другой — шесть месяцев. Одного продакт соберёт сам на n8n. Другому нужна выделенная ML-команда. Один стоит $500 в месяц. Другой нагенерит шестизначный счёт за LLM в год.
Ассистент клиентской поддержки и голосовой шопинг-агент — оба называются «агентами», но требуют разных архитектур, разных команд, разной инфраструктуры, разных сроков. Пока ты не видишь эти различия, любая попытка сравнивать «effort» и «impact» — по сути, гадание.
Относиться к архитектурно разным продуктам как к одной категории — значит делать нормальную приоритизацию практически невозможной. Приоритизация ломается не потому, что команды плохо планируют, а потому, что они сравнивают яблоки, апельсины и реактивные двигатели в одной таблице.
Прежде чем решить, какого агента строить первым, ответь на более базовый вопрос: какой тип агента, собственно, предлагает каждая идея?
Это определит почти всё, что важно для планирования:
Другими словами, категоризация — это не технический ритуал. Это фундамент умной приоритизации.
Этот пост даёт тебе фреймворк принятия решений, который ты можешь применить к текущей roadmap прямо сегодня.
Мы собрали его из паттернов, которые видели, помогая организациям превращать агентские идеи в реальные production-системы. Работая с enterprise-командами Fortune 500 — Jack in the Box, Tripadvisor, The Home Depot — мы обнаружили, что группировка идей по их архитектуре разблокирует приоритизацию и заметно ускоряет разработку и запуск. Эти различия отражают и то, как индустрия в целом начинает классифицировать AI-агентов — от automation workflows до reasoning-систем и multi-agent-сетей (см. статью Levels of Autonomy for AI Agents и разбор Types of AI agents от IBM). Это же — фундамент того, как архитектурно устроены мегапопулярные OpenClaw и Claude Code.
Если ты сейчас смотришь в бэклог агентских идей и пытаешься понять, что строить первым, вот что у тебя будет к концу поста:
Ты сможешь посмотреть на свой бэклог и понять: какие идеи отгружаются за шесть недель и дают быстрый ROI, какие требуют три месяца, но двинут выручку, а какие — полугодовая ставка, которая имеет смысл только при правильных ресурсах и правильно выставленных ожиданиях.
И всё это — начиная с признания того, что «агент» — это зонтичный термин для очень разных систем.
Каждая «агентская» идея попадает в одну из трёх архитектурных категорий.

**Category 1: Deterministic automation (детерминированная автоматизация)
**Ты определяешь весь флоу. AI делает контент на конкретных шагах. Пример: n8n или Zapier-воркфлоу с LLM-нодами. Сюда попадает большинство агентских возможностей, и с этого большинству команд стоит начинать. Такие проекты быстрее запускаются и приносят измеримый ROI быстрее всех.
**Category 2: Reasoning and acting agents (агенты с рассуждением и действием)
**AI сам решает, что делать дальше, используя доступные инструменты. Пример: Cursor, Lovable или агенты, собранные на LangGraph, CrewAI, Google ADK и т.п. Обычно такие инициативы идут после Category 1 — когда более ценные задачи требуют гибкости и динамического принятия решений, которых воркфлоу не вывозит.
**Category 3: Multi-agent networks (сети из нескольких агентов)
**Несколько специализированных агентов координируются между собой. Пример: enterprise-системы на ADK или AutoGen. Такие проекты обычно приберегают на потом — когда нужно согласовывать работу нескольких команд по доменам, и почти никогда не должны быть стартовой точкой в roadmap.
Несколько примеров «агентов» по категориям, чтобы разница стала нагляднее:

Организации часто пытаются решать Category 1-задачи на Category 2-фреймворках — over-engineering, лишняя сложность и расходы. Реже, но с худшими последствиями, пытаются решать Category 2-задачи инструментами Category 1 — в проде такое ломается, потому что инструмент не тянет.
Разберём каждую категорию подробнее — начнём с рабочей лошадки, Category 1.
Это воркфлоу, где ты сам определяешь каждый шаг, каждую ветку, каждую точку принятия решения. LLM на конкретных нодах делает понимание естественного языка и генерацию — но флоу контролируешь ты. Думай о них как об «умных блок-схемах»: путь рисуешь ты, контент делает AI.
Самые частые инструменты для детерминированной автоматизации: n8n, Zapier, Make.com, OpenAI AgentKit, Lindy, Gumloop. Они построены вокруг явных триггеров и заранее определённой логики ветвления. Ты задаёшь воркфлоу, а LLM занимается только классификацией, извлечением или драфтингом внутри этих границ.
Если в бэклоге смесь агентских идей, Category 1-проекты почти всегда — самая умная отправная точка. Такие инициативы проще всего спланировать и сопряжены с наименьшим риском.
Они лучше всего подходят, когда процесс уже хорошо описан, а цель — автоматизировать повторяющуюся, объёмную работу. Если нужен быстрый, измеримый ROI, ограничена AI-инженерная мощность или на тебя давят с результатами в неделях, а не месяцах — Category 1 почти всегда правильная отправная точка.
Большинство инициатив в этой категории имеют схожий профиль по ряду критериев:

Именно это сочетание — быстрые сроки, скромные ресурсы, понятный бизнес-эффект — делает Category 1-инициативы сильными «ранними победами». Они приносят ценность сразу и параллельно накапливают уверенность в организации для более сложных усилий потом.
Если ты можешь нарисовать весь процесс как блок-схему с понятными точками решения — продукт относится к Category 1. Ещё признаки Category 1:
По нашему опыту с клиентами, это покрывает 60-70% агентских возможностей. Возвращаясь к типичному списку, вот отличный пример Category 1-продукта: «Нам нужен AI-агент, который принимает входящие письма от клиентов, читает их, понимает запрос, тянет релевантную информацию из документации, составляет черновик ответа и отправляет на апрув команде».
На первый взгляд — кажется, нужен сложный reasoning. Но когда распишешь, что реально должно произойти, всё оказывается удивительно детерминированным:

Каждый шаг предсказуем. «Интеллект» нужен для того, чтобы понять письмо и сгенерировать хороший ответ, а не чтобы решать, что делать дальше. Это Category 1.
Отличных примеров automation-агентов — куча; вот один мой собственный.
Я люблю Airbnb, но терпеть не могу часами искать лучшие варианты. Поэтому собрал агента, который возьмёт мой точный запрос типа «Современная квартира в Париже рядом с вокзалами с 20 по 26 марта. Для пары» (им уже воспользовались более 10 000 человек) и сам прогонит поиск. Вот как собрать такого же.
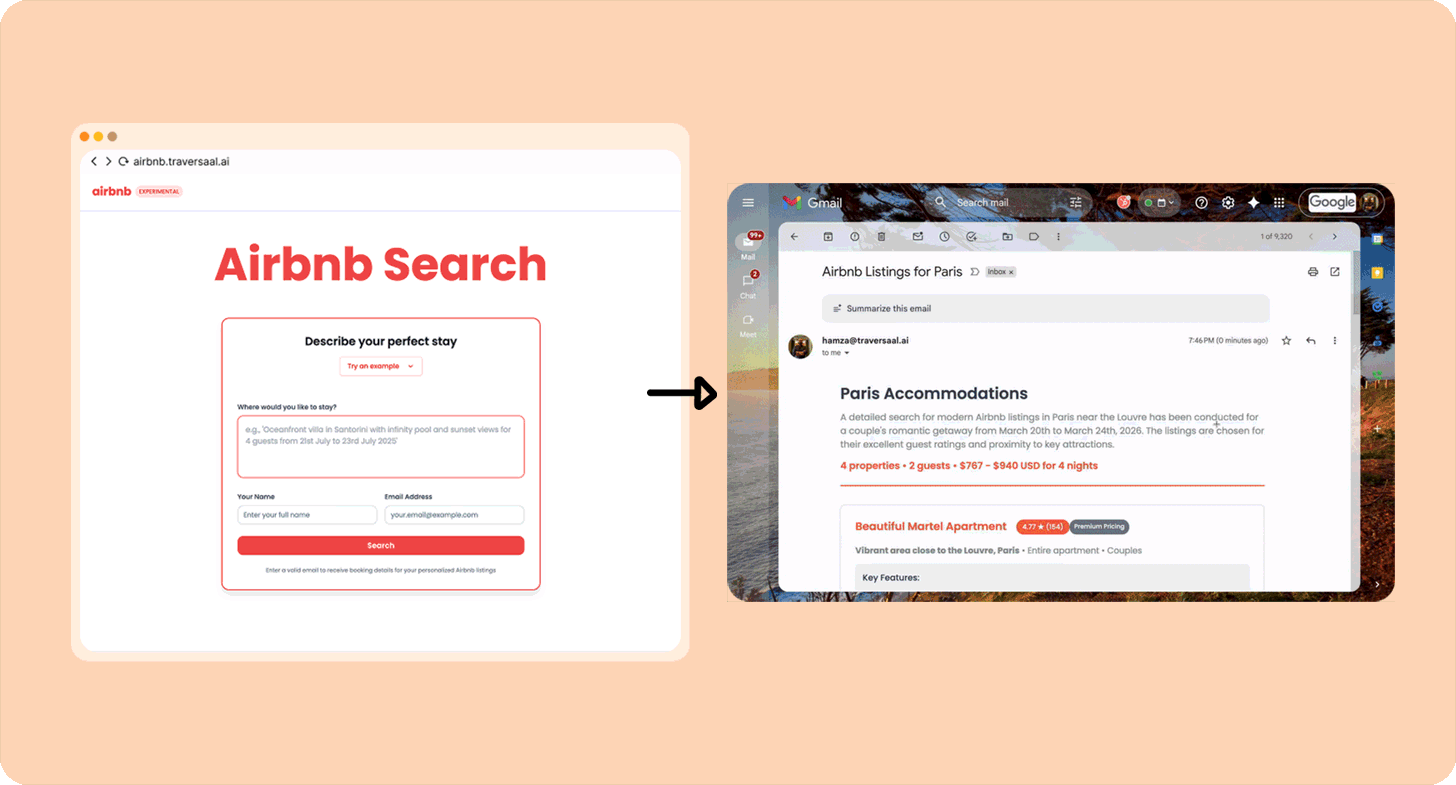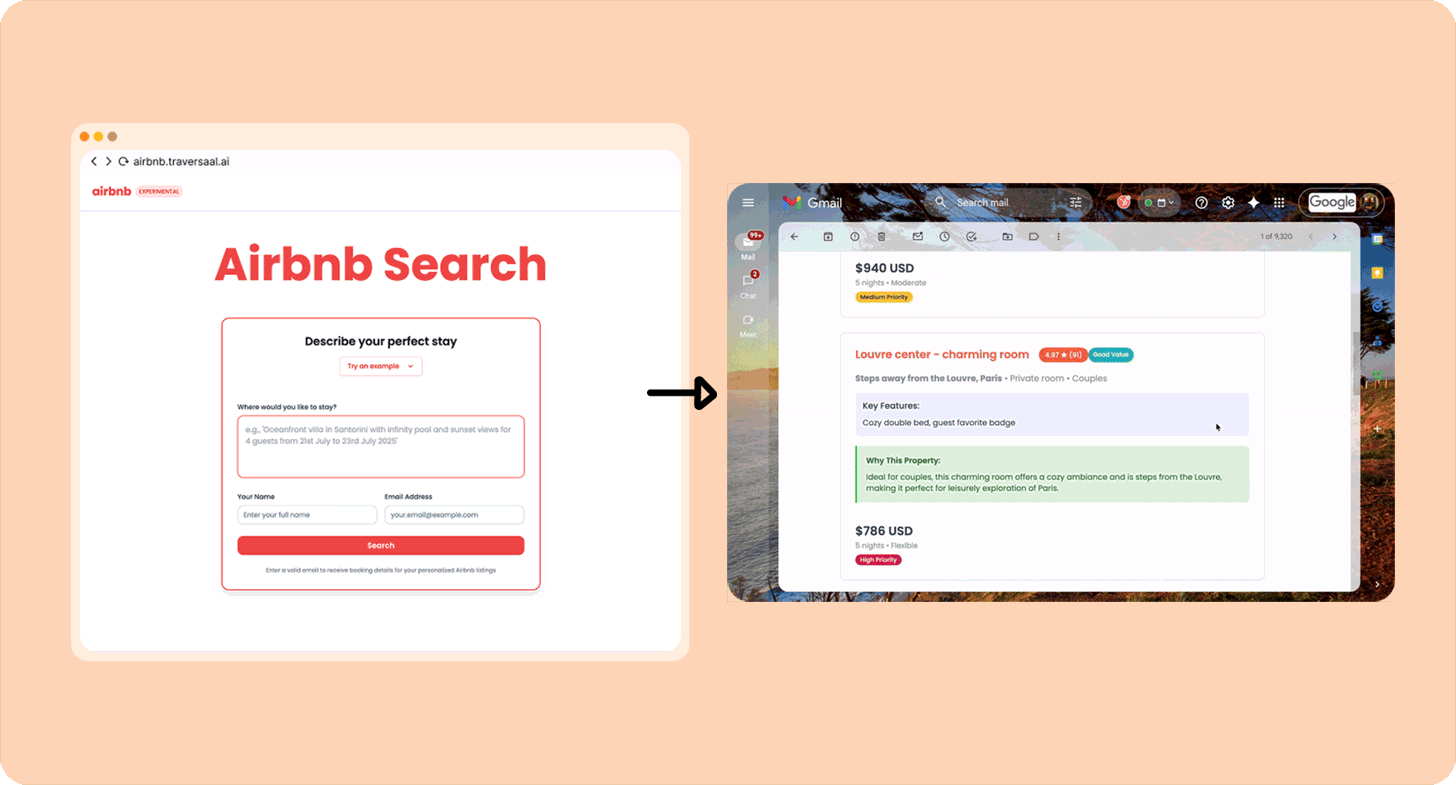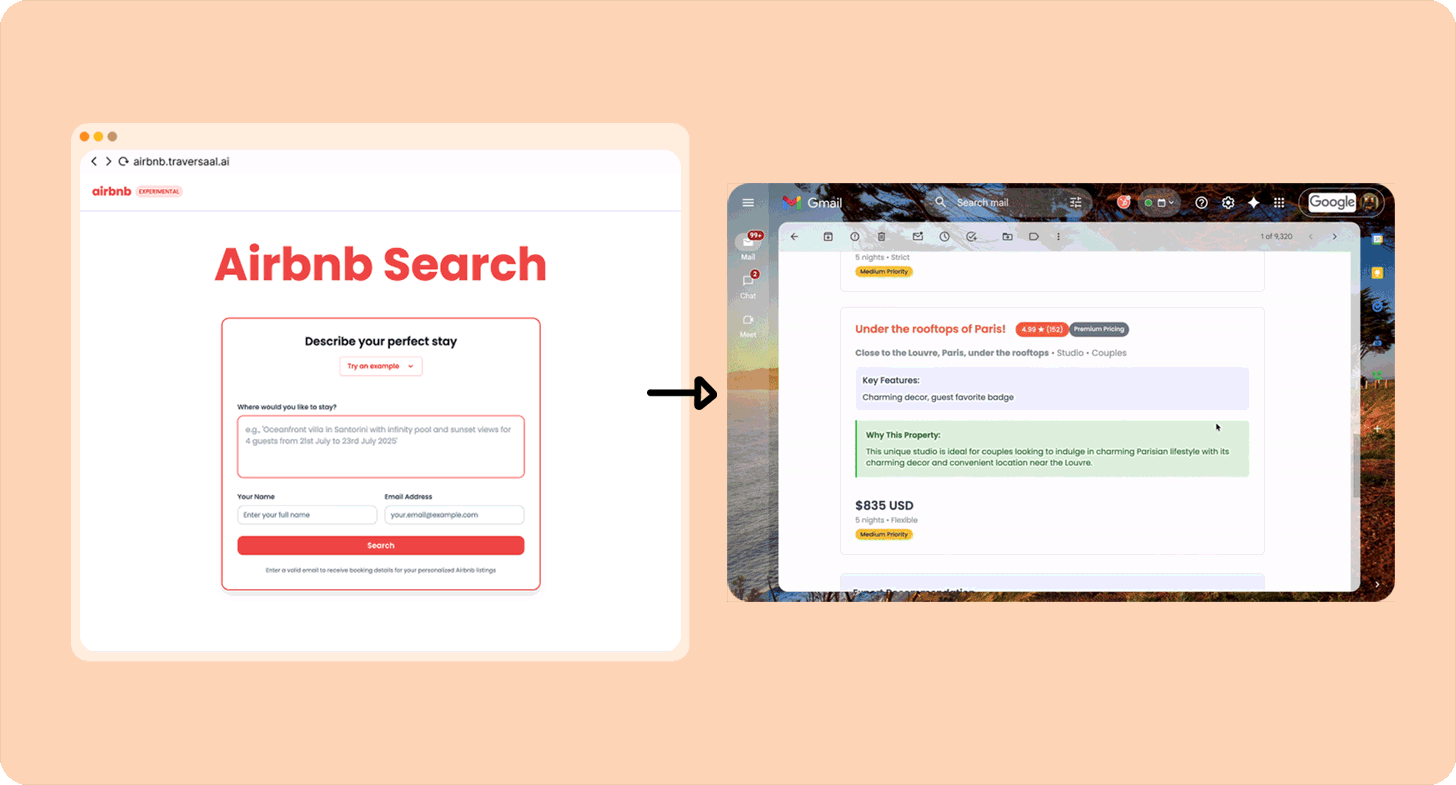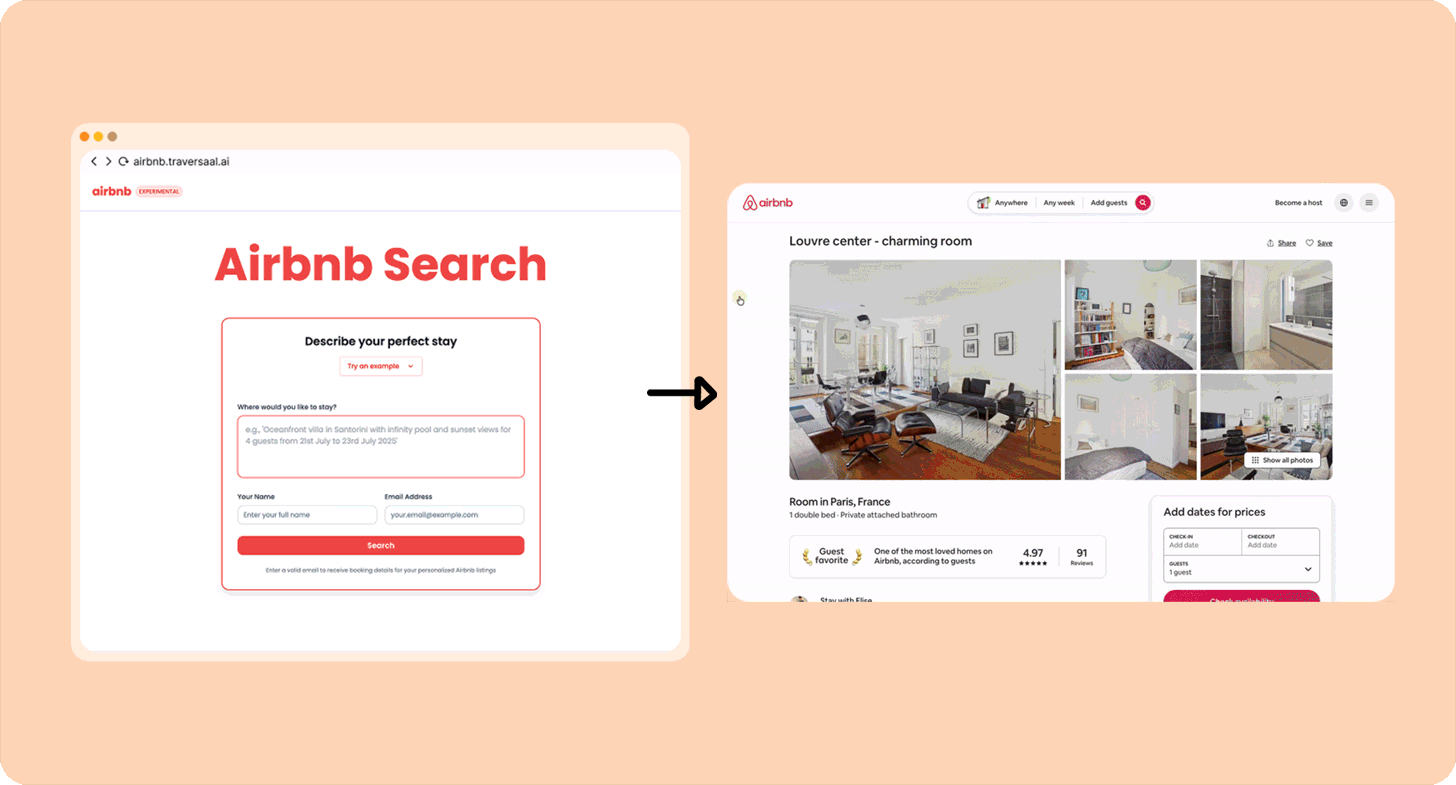

Другие примеры Category 1-«агентов»:
Метрики ниже отвечают на простой вопрос: автоматизировал ли агент правильный процесс — или идею стоит переосмыслить/перекроить?
Детерминированного агента для автоматизации email-ответов можно оценивать так:
Вот workflow completion rate из реального Category 1-кейса — email support agent, сделанный SaaS-компанией, с которой мы работали:
Когда метрики стабилизируются и стоимость идёт вниз — воркфлоу делает то, что должен. Если completion остаётся низким или доля ручных вмешательств высокой, значит, задача недостаточно детерминированная для этой категории.
Ты поймёшь, что нужна другая архитектура, когда:
Если ты ловишь сразу несколько таких сигналов — задача больше не подходит под детерминированный воркфлоу, и стоит смотреть в сторону Category 2.
Вместо того чтобы задавать флоу, ты задаёшь доступные инструменты, а LLM автономно решает, что делать дальше. Агент работает в цикле: observe → reason → act → observe result → повторить.
Ключевая характеристика: инструменты контролируешь ты, reasoning — LLM.
Самые частые инструменты для сборки ReAct-агентов: LangGraph, CrewAI, AutoGen и другие orchestration-библиотеки, поддерживающие tool use, память и динамическое планирование.

Category 2 — это про ситуации, где запросы пользователя расплывчатые, воркфлоу нельзя описать заранее, а реальная ценность — в гибком, контекстном принятии решений. Если нужен агент, который умеет рассуждать через несколько инструментов, вести диалоги или динамически подстраиваться под новые входы — это Category 2.
Category 2-продукты сложнее планировать и несут больший execution-риск, чем Category 1. Большинство инициатив этой категории имеют похожий профиль:

Сочетание более длинных сроков, специализированной экспертизы и более высоких затрат — вот что делает Category 2 мощным, но более требовательным, чем Category 1. Если в бэклоге есть задачи, которые реально требуют reasoning и динамики — приоритизация Category 2 становится критичной. Они открывают кейсы, которые детерминированная автоматизация не тянет, и раскрывают более продвинутые агентские сценарии с высокой отдачей.
Продукт относится к Category 2, если один и тот же пользовательский запрос может каждый раз запускать разные последовательности действий. То есть путь определяет не ты — его определяет LLM. Это ключевое отличие от Category 1. Ещё признаки Category 2-продукта:
В нашей работе с клиентами это правильный выбор для 25-30% агентских возможностей. За примером вернёмся к голосовому шопинг-ассистенту из начала поста.
Клиенты должны уметь искать товары голосом, загружать фото для поиска похожего, проверять статус заказа, обновлять предпочтения, инициировать возвраты — и всё это через разговор.
На первый взгляд — это Category 1. Просто опиши интенты и маршрутизируй, правда? Но в реальности живые разговоры не идут по фиксированным путям. Чтобы понять почему, разберём одно взаимодействие.
Клиент загружает фото ботинок и говорит:
«Эти маловаты. Нужен размер больше, и доставка до четверга».
Вот что происходит под капотом:
Эту последовательность нельзя определить заранее.
Один и тот же запрос запускает разные последовательности действий — в зависимости от того, что решил reasoning-цикл.

Другие примеры Category 2-«агентов»:
Reasoning-агентов оценивают по тому, помогают ли они пользователям достигать цели на разных путях — оставаясь достаточно эффективными, чтобы оправдать стоимость.
Эти метрики отвечают на вопрос: был ли динамический reasoning необходим — или задачу стоило упростить до более низкой категории?
Вот метрики из реального кейса — voice + image шопинг-ассистент для ритейлера товаров для дома, который мы строили:
Результат: точность распознавания картинок выросла с 76% до 91%, прирост конверсии — с +8% до +22%, CSAT — с 4.0 до 4.5.
Когда task completion растёт, а длина диалога, число tool calls и стоимость сессии падают — reasoning-цикл агента приносит ценность. Если метрики стоят, а цена держится высокой — скорее всего, задача over-scoped или её лучше решить детерминированным подходом Category 1.
Ты поймёшь, что нужна другая архитектура, когда:
Если у тебя 2-3 таких сигнала одновременно — пора смотреть в сторону Category 3.
Вместо одного агента, вызывающего инструменты, у тебя несколько специализированных агентов, которые координируются. Каждым владеет своя команда, каждый ведёт свой домен и может попросить помощи у других агентов.
Ключевая характеристика Category 3: агенты делегируют другим агентам, а не просто API.
Category 2 vs. Category 3 — в чём разница?
Каждый агент в сети сам по себе — reasoning-система, которая умеет разбирать запрос. Но они координируются, делегируя сложные задачи друг другу, а не пытаясь тащить всё в одном.
На практике шопинг-агенту не обязательно знать, как работает inventory-forecasting — ему достаточно найти и поговорить с Inventory Agent, которым владеет ops-команда. Когда ops прокачают своего агента, шопинг автоматически выиграет.
Для Category 3-проектов можно использовать те же фреймворки, что и для одиночных reasoning-агентов, но их нужно дополнить слоями координации: например, Google A2A-протоколом для структурированного agent-to-agent делегирования и enterprise-оркестраторами вроде Temporal, Kafka или Step Functions — для discovery, маршрутизации и длительных workflow.
Category 3 почти никогда не бывает отправной точкой в roadmap. Она становится актуальной, только когда организация уже гоняет в проде несколько агентов и они должны работать вместе.
Дело в том, что Category 3 — самый сложный и ресурсоёмкий тип агентской работы. Типичный проект тут включает:

Большинству организаций стоит инвестировать в Category 3 только после успехов в Category 1 и Category 2. Один orchestrator-агент (Category 2) обычно проще и эффективнее — пока реальная кросс-командная координация не станет неизбежной.
Признаки Category 3-продуктов:
Multi-agent-сети пока редкость — их делают меньше 5-10% команд, строящих агентов. Мы ожидаем, что в ближайшие 12-24 месяца adoption вырастет: всё больше компаний получат несколько команд, независимо разворачивающих production-агентов, и координация станет неизбежной.
Мы уже начали видеть, как multi-agent-сети появляются у Fortune 500-ритейлеров и сетей питания в США, с которыми работаем. У них есть отдельные команды, которые хотят строить специализированных агентов для:
Но эти агенты должны работать вместе, чтобы решать важные сценарии:
Ни одна команда не построит всё это в одиночку. Каждому агенту нужно развиваться независимо. Но им нужно координироваться, чтобы закрывать продуктовые возможности.
Это Category 3.

Category 3-системы успешны, если много независимых агентов умеют работать вместе, не создавая хрупкости. Для оценки лучше фокусироваться на пяти сигналах:
Вот как Category 3-метрики сработали в реальном кейсе — крупный ритейлер развернул multi-agent-сеть на customer service, inventory, logistics и quality monitoring:
Результат: новых агентов и команды добавляли без деградации надёжности, хвостов латентности и стоимости задачи.
Когда cross-agent success rate и перцентили латентности держатся стабильно при добавлении новых агентов, а стоимость сложной задачи растёт медленно или стоит на месте — multi-agent-сеть оправдана для этого продукта. Если с каждым новым агентом взлетают failure rate, хвосты латентности или время интеграции — скорее всего, система перекоординирована или преждевременно усложнена. Смотри в сторону Category 1 или Category 2.
Вот систематический процесс, как понять, какая категория нужна твоей агентской возможности.

Для каждой агентской идеи в бэклоге задай эти вопросы:

На практике не все команды попадают с первого раза — и это нормально. Цель triage — не гарантировать идеальное решение в день первый. Цель — помочь тебе сделать лучшую стартовую ставку с имеющейся информацией и быстро скорректироваться по сигналам из реальной жизни.
Если ты стартовал не в той категории, сигналы обычно приходят быстро:
Ключевое — относиться к категоризации как к живому решению, а не как к постоянному ярлыку. Пилотируй рано, мерь честно и будь готов рефакторить архитектуру, если доказательства ведут в другую сторону. Выбор «не той» категории на несколько недель стоит куда дешевле, чем вообще не иметь фреймворка.
В реальности production-агентские системы редко придерживаются одной парадигмы. Два самых часто разбираемых примера — OpenClaw и Claude Code.
OpenClaw — в первую очередь ReAct-агент. Он крутит непрерывный цикл reasoning → выбор инструмента → действие — в мессенджерах вроде WhatsApp и Telegram. Но пользователь может сконфигурировать несколько специализированных агентов, которые координируются на сложных задачах — и тогда это уходит в multi-agent-зону, если задача требует.
Claude Code идёт дальше. В его ядре — ReAct reasoning loop: модель решает, что делать, зовёт инструмент, смотрит результат и продолжает. Поверх — детерминированная система хуков, которая запускает скрипты на событиях жизненного цикла (сохранение файла, shell-команда) — без участия LLM вообще. А когда задача слишком большая или рискованная для одного контекст-окна, он порождает sub-агентов с изолированными контекстами, которые координируются через структурированный approval-паттерн.
Ни одна из этих систем не является ни чисто детерминированной, ни чисто ReAct, ни чисто multi-agent. Они слоёные — каждая парадигма закрывает конкретный режим отказа, который другие не вывозят. Детерминированный слой — для аудируемости. ReAct — для гибкого reasoning. Multi-agent — для параллельности и изоляции.
Вот настоящее дизайн-решение: не «какую архитектуру выбрать», а «когда текущий слой перестал справляться — и пора подключать следующий».
Этот фреймворк — не единственный способ думать про агентские архитектуры. Но он себя оправдал для команд, у которых в бэклоге лежит список «агентских» идей, и они пытаются понять, что строить первым и как выстраивать инвестиции.
Главный инсайт: не все агенты одинаковы. Детерминированная автоматизация, reasoning-агент и multi-agent-сеть требуют совершенно разных архитектур, сроков, бюджетов и экспертизы. Относиться к ним одинаково — именно поэтому столько инициатив стопорится, а приоритизация кажется невозможной.
Вот где категоризация становится инструментом roadmap. Как только идеи разложены по категориям, приоритизация следует сама:
Другими словами, категории задают порядок: стартуй просто, докажи ценность и наращивай сложность только если задача того требует.
Команды, которые успешно отгружают агентские системы, — это те, кто умеет быстро определять категорию задачи и сопротивляется соблазну переусложнять.
Три вопроса для каждой агентской идеи:
Если ты не можешь чётко ответить на все три — ты не готов начинать стройку. И это нормально. Лучше стартовать с Category 1-автоматизации, которая отгрузится за шесть недель и даст измеримую ценность, чем запустить Category 3-multi-agent, который «на 90% готов» спустя полгода.
Вот так этот фреймворк помогает с приоритизацией: он превращает запутанный список «агентов» в чёткую практическую последовательность — что строить сейчас, что дальше, а что оставить на потом.
Спасибо, Hamza и Jaya!
Продуктивной и осмысленной недели 🙏
Если рассылка полезна — поделись с другом и подпишись, если ещё не. Доступны групповые скидки, подарки и реферальные бонусы.
Искренне твой,
Lenny 👋